In this DIY we will see how to set up a single-node Hadoop cluster backed by the Hadoop Distributed File System (HDFS), running on Ubuntu-12.04. The main goal of this tutorial is to get a simple Hadoop installation up and running so that you can play around with the software and learn more about it.
This tutorial has been tested with the following software versions:
Step 1: Prerequisites
1. Download Hadoop
Hadoop-1.2.1 can be downloaded from here. Select a mirror, then select 'hadoop-1.2.1/' directory and download hadoop-1.2.1.tar.gz. I assume you have downloaded it into your '/home/user_name/Downloads' directory.
2. Install JDK 8
Hadoop requires a working Java installation. So, open up a terminal and run the following
It will take some time to download and install so sit back and wait. Once it's done then we have to add the JAVA_HOME to the Ubuntu environment. Run the following in a terminal to open up the /etc/environment file.
Now, append the following at the end of the file and save it:
3. Adding a dedicated Hadoop system user
We will use a dedicated Hadoop user account for running Hadoop. While that’s not required it is recommended because it helps to separate the Hadoop installation from other software applications and user accounts running on the same machine. Following commands are used for our purpose, image 1 shows a typical output screen of the same.
4. Installing and configuring SSH Server
Hadoop requires SSH access to manage its nodes, i.e. remote machines plus your local machine if you want to use Hadoop on it (which is what we want to do in this short tutorial). For our single-node setup of Hadoop, we therefore need to configure SSH access to localhost for the hduser user we created in the previous section. Install openssh server as:
Now, open a new terminal and switch to hduser then we have to generate an SSH key for the hduser user
The second line will create an RSA key pair with an empty password. Generally, using an empty password is not recommended, but in this case it is needed to unlock the key without your interaction (you don’t want to enter the pass-phrase every time Hadoop interacts with its nodes). The output will look like this:
Now we have to enable SSH access to your local machine with this newly created key.
The final step is to test the SSH setup by connecting to our local machine with the hduser user. The step is also needed to save our local machine’s host key fingerprint to the hduser user's known_hosts file.
The output will look like this:
NOTE: If you get an error saying “ssh: connect to host localhost port 22: Connection refused”, then you have not installed the ‘openssh-server’ properly, install it first.
5. Disabe IPv6
Close the current terminal by repeatedly typing "exit" until it doesn't get closed. Open a new terminal and open the file /etc/sysctl.conf
Now append the following lines at the end of the file and save it.
You have to restart your system in order to make the changes take effect. You can check whether IPv6 is enabled on your machine with the following command:
A return value of 0 means IPv6 is enabled (image 4), a value of 1 means disabled (image 5, that’s what we want).
After restart
Step 2: Install Hadoop
1. Extract Hadoop and modify the permissions
Extract the contents of the Hadoop package to a location of your choice. Say ‘/usr/local/hadoop’. Make sure to change the owner of all the files to the hduser user and hadoop group. But first move the downloaded hadoop-1.2.1.tar.gz to ‘/user/local/’ (image 6).
2. Update '$HOME/.bashrc' of hduser
This tutorial has been tested with the following software versions:
- Ubuntu -12.04 (LTS)
- Hadoop- 1.2.1, released Aug, 2013
- JDK- 8 update 5
Step 1: Prerequisites
1. Download Hadoop
Hadoop-1.2.1 can be downloaded from here. Select a mirror, then select 'hadoop-1.2.1/' directory and download hadoop-1.2.1.tar.gz. I assume you have downloaded it into your '/home/user_name/Downloads' directory.
2. Install JDK 8
Hadoop requires a working Java installation. So, open up a terminal and run the following
| 1 | sudo add-apt-repository ppa:webupd8team/java |
| 2 | sudo apt-get update && sudo apt-get install oracle-java8-installer |
It will take some time to download and install so sit back and wait. Once it's done then we have to add the JAVA_HOME to the Ubuntu environment. Run the following in a terminal to open up the /etc/environment file.
| 1 | sudo gedit /etc/environment |
Now, append the following at the end of the file and save it:
| JAVA_HOME="/usr/lib/jvm/java-8-oracle" |
3. Adding a dedicated Hadoop system user
We will use a dedicated Hadoop user account for running Hadoop. While that’s not required it is recommended because it helps to separate the Hadoop installation from other software applications and user accounts running on the same machine. Following commands are used for our purpose, image 1 shows a typical output screen of the same.
| 1 | sudo addgroup hadoop |
| 2 | sudo adduser --ingroup hadoop hduser |
 |
| Image 1. Adding a Hadoop System User. |
4. Installing and configuring SSH Server
Hadoop requires SSH access to manage its nodes, i.e. remote machines plus your local machine if you want to use Hadoop on it (which is what we want to do in this short tutorial). For our single-node setup of Hadoop, we therefore need to configure SSH access to localhost for the hduser user we created in the previous section. Install openssh server as:
| 1 | sudo apt-get install openssh-server |
Now, open a new terminal and switch to hduser then we have to generate an SSH key for the hduser user
| 1 | su - hduser |
| 2 | ssh-keygen -t rsa -P "" |
The second line will create an RSA key pair with an empty password. Generally, using an empty password is not recommended, but in this case it is needed to unlock the key without your interaction (you don’t want to enter the pass-phrase every time Hadoop interacts with its nodes). The output will look like this:
 |
| Image 2. Creating an RSA Key Pair. |
Now we have to enable SSH access to your local machine with this newly created key.
| 1 | cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys |
The final step is to test the SSH setup by connecting to our local machine with the hduser user. The step is also needed to save our local machine’s host key fingerprint to the hduser user's known_hosts file.
| 1 | ssh localhost |
The output will look like this:
 |
| Image 3. Testing the ssh Setup. |
NOTE: If you get an error saying “ssh: connect to host localhost port 22: Connection refused”, then you have not installed the ‘openssh-server’ properly, install it first.
5. Disabe IPv6
Close the current terminal by repeatedly typing "exit" until it doesn't get closed. Open a new terminal and open the file /etc/sysctl.conf
| 1 | sudo gedit /etc/sysctl.conf |
Now append the following lines at the end of the file and save it.
| net.ipv6.conf.all.disable_ipv6 = 1 |
| net.ipv6.conf.default.disable_ipv6 = 1 |
| net.ipv6.conf.lo.disable_ipv6 = 1 |
You have to restart your system in order to make the changes take effect. You can check whether IPv6 is enabled on your machine with the following command:
| 1 | cat /proc/sys/net/ipv6/conf/all/disable_ipv6 |
A return value of 0 means IPv6 is enabled (image 4), a value of 1 means disabled (image 5, that’s what we want).
 |
| Image 4. IPv6 Enabled. |
After restart
 |
| Image 5. IPv6 Disabled. |
Step 2: Install Hadoop
1. Extract Hadoop and modify the permissions
Extract the contents of the Hadoop package to a location of your choice. Say ‘/usr/local/hadoop’. Make sure to change the owner of all the files to the hduser user and hadoop group. But first move the downloaded hadoop-1.2.1.tar.gz to ‘/user/local/’ (image 6).
| 1 | sudo mv /home/user_name/Downloads/hadoop-1.2.1.tar.gz /usr/local |
| 2 | cd /usr/local |
| 3 | sudo tar xzf hadoop-1.2.1.tar.gz |
| 4 | sudo mv hadoop-1.2.1 hadoop |
| 5 | sudo chown –R hduser:hadoop hadoop |
 |
| Image 6. Extracting and Modifying the Permissions. |
2. Update '$HOME/.bashrc' of hduser
Open the $HOME/.bashrc file of user hduser
| 1 | sudo gedit /home/hduser/.bashrc |
and add the following lines at the end:
| # Set Hadoop-related environment variables |
| export HADOOP_PREFIX=/usr/local/hadoop |
| # Set JAVA_HOME (we will also configure JAVA_HOME directly for Hadoop later on) |
| export JAVA_HOME=/usr/lib/jvm/java-8-oracle |
| # Some convenient aliases and functions for running Hadoop-related commands |
| unalias fs &> /dev/null |
| alias fs="hadoop fs" |
| unalias hls &> /dev/null |
| alias hls="fs -ls" |
| # If you have LZO compression enabled in your Hadoop cluster and |
| # compress job outputs with LZOP (not covered in this tutorial): |
| # Conveniently inspect an LZOP compressed file from the command |
| # line; run via: |
| # |
| # $ lzohead /hdfs/path/to/lzop/compressed/file.lzo |
| # |
| # Requires installed 'lzop' command. |
| # |
| lzohead () { |
| hadoop fs -cat $1 | lzop -dc | head -1000 | less |
| } |
| # Add Hadoop bin/ directory to PATH |
| export PATH=$PATH:$HADOOP_PREFIX/bin |
Step 3: Configuring Hadoop
Now we have to configure the directory where Hadoop will store its data files, the network ports it listens to, etc. Our setup will use Hadoop’s Distributed File System, HDFS, even though our little cluster only contains our single local machine.
1. Setting up the working directory
We will use the directory ‘/app/hadoop/tmp’ in this tutorial. Hadoop’s default configurations use hadoop.tmp.dir as the base temporary directory both for the local file system and HDFS, so don’t be surprised if you see Hadoop creating the specified directory automatically on HDFS at some later point. Now we create the directory and set the required ownerships and permissions:
| 1 | sudo mkdir -p /app/hadoop/tmp |
| 2 | sudo chown hduser:hadoop /app/hadoop/tmp |
| 3 | sudo chmod 750 /app/hadoop/tmp |
If you forget to set the required ownerships and permissions, you will see a java.io.IOException when you try to format the name node in the next section.
2. Configuring Hadoop setup files
I. hadoop-env.sh
The only required environment variable we have to configure for Hadoop is JAVA_HOME. Open conf/hadoop-env.sh (if you used the installation path in this tutorial, the full path is /usr/local/hadoop/conf/hadoop-env.sh) and set the JAVA_HOME environment variable to the java8 directory.
| 1 | sudo gedit /usr/local/hadoop/conf/hadoop-env.sh |
Replace
 |
| Image 7. Replace this . |
With
| # The java implementation to use. Required. |
| export JAVA_HOME=/usr/lib/jvm/java-8-oracle |
II. core-site.xml
Open up the file /usr/local/hadoop/conf/core-site.xml
| 1 | sudo gedit /usr/local/hadoop/conf/core-site.xml |
and add the following snippet between <configuration>...</configuration> tags (see image 8). You can leave the settings below “as is” with the exception of the hadoop.tmp.dir parameter – this parameter you must change to a directory of your choice.
| <property> |
| <name>hadoop.tmp.dir</name> |
| <value>/app/hadoop/tmp</value> |
| <description>A base for other temporary directories.</description> |
| </property> |
| <property> |
| <name>fs.default.name</name> |
| <value>hdfs://localhost:54310</value> |
| <description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description> |
| </property> |
 |
| Image 8. Add as Shown. |
III. mapred-site.xml
Open up the file /usr/local/hadoop/conf/mapred-site.xml
| 1 | sudo gedit /usr/local/hadoop/conf/mapred-site.xml |
add the following snippet between <configuration>...</configuration> tags.
| <property> |
| <name>mapred.job.tracker</name> |
| <value>localhost:54311</value> |
| <description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task.</description> |
| </property> |
IV. hdfs-site.xml
Open up the file /usr/local/hadoop/conf/hdfs-site.xml
| 1 | sudo gedit /usr/local/hadoop/conf/hdfs-site.xml |
add the following snippet between <configuration>...</configuration> tags.
| <property> |
| <name>dfs.replication</name> |
| <value>1</value> |
| <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time.</description> |
| </property> |
Step 4: Formatting the HDFS Filesystem via the Namenode
The first step to starting up your Hadoop installation is formatting the Hadoop filesystem which is implemented on top of the local filesystem of your “cluster” (which includes only your local machine if you followed this tutorial). You need to do this the first time you set up a Hadoop cluster.
NOTE: Do not format a running Hadoop filesystem as you will lose all the data currently in the cluster (in HDFS)!
To format the filesystem (which simply initializes the directory specified by the dfs.name.dir variable), run the commands in a new terminal
| 1 | su - hduser |
| 2 | /usr/local/hadoop/bin/hadoop namenode -format |
The output will look like this:
 |
| Image 9. Formatting Namenode. |
Step 5: Starting your Single-Node Cluster
1. Run the command:
| 1 | /usr/local/hadoop/bin/start-all.sh |
This will start a Namenode, a Datanode, a Jobtracker and a Tasktracker on your machine. The output will look like this:
 |
| Image 10. Starting the Single-Node Cluster. |
2. Check whether the expected Hadoop processes are running:
| 1 | cd /usr/local/hadoop |
| 2 | jps |
The output will look like this (Process ids and ordering of processes may differ):
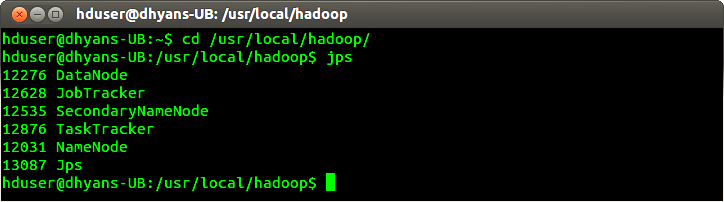 |
| Image 11. Running Hadoop Processes. |
If all the six processes are running then your Hadoop is working fine.
3. You can also check if Hadoop is listening on the configured ports. Open a new terminal and run
| 1 | sudo netstat -plten | grep java |
Output will look like this:
 |
| Image 12. Hadoop is Listening. |
Step 6: Stopping your Single-Node Cluster
To stop all the daemons running on your machine, run the command:
| 1 | /usr/local/hadoop/bin/stop-all.sh |
The output will look like this:
 |
| Image 13. Stopping the Single-Node Cluster. |
Congratulations! You have successfully installed your Hadoop. You can start working with Hadoop now; just remember to start your cluster first. Happy Hadooping !
— * — * — * — * —
Sources
- http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-single-node-cluster/
- http://www.webupd8.org/2012/09/install-oracle-java-8-in-ubuntu-via-ppa.html
Comments
Post a Comment